

Nell’ambito della drug discovery, lo sviluppo di nuovi antibiotici è un punto cruciale, vista la portata del fenomeno dell’antibiotico resistenza (Antimicrobial Resistance, AMR).
Nonostante l’urgenza, l’antibiotic-discovery, è stagnante per motivi prevalentemente economici. Strumenti di IA rappresentano un valido aiuto per tagliare tempi e costi di produzione, ma non senza limitazioni.
L’antibiotic discovery non conviene economicamente alle Pharma, l’UK ci prova con il Netflix model
I freni allo sviluppo di nuovi antibiotici sono prevalentemente economici: la prima metà del Novecento, sono stati gli anni d’oro della ricerca e sviluppo di nuovi composti antibatterici, generosamente supportata da investimenti pubblici e privati – spinti da una mancanza di trattamenti efficaci contro le infezioni. Dagli anni Ottanta i finanziamenti sono stati spostati verso altri ambiti come i tumori, in parte per ragioni economiche, in parte perché erano cambiate le priorità in materia di salute pubblica, e le infezioni batteriche, grazie agli antibiotici, non rappresentavano più una minaccia.
Ora il fenomeno dell’AMR ha cambiato la lista delle priorità, ma ciò non è coinciso con un re indirizzamento dei fondi, e molte delle farmaceutiche hanno abbandonato quest’area per mancanza di incentivi finanziari, come riportato dall’analisi pubblicata qualche anno fa dalla rivista Nature.
I nuovi antibiotici, infatti, verrebbero usati in maniera parsimoniosa per trattare i pazienti con infezioni multi-resistenti, per cui chi sviluppa il farmaco non riesce ad avere un ritorno economico di tutti i soldi spesi per la ricerca e lo sviluppo – si parla di circa 1.5 milioni di dollari per lo sviluppo di un farmaco che può richiedere fino ai 10 anni.
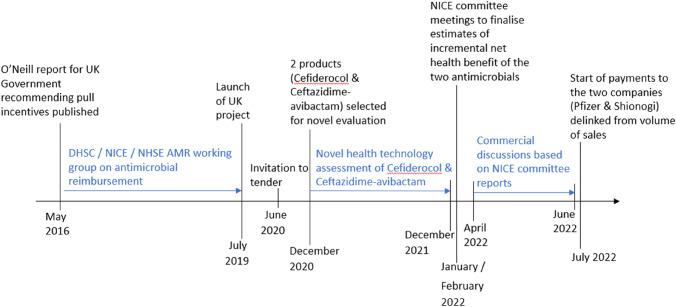
Per incentivare la produzione di nuovi antibiotici da parte delle aziende farmaceutiche, nel 2019 l’Inghilterra ha lanciato il così detto “Netflix model”.
Questo modello di rimborso non è basato sul numero di dosi somministrate, ma sull’accesso al farmaco e prevede che il governo, in questo caso il National Health Service (NHS), paghi le compagnie farmaceutiche un determinato prezzo per antibiotico, a prescindere dalla quantità che verrà acquistata effettivamente per trattare i pazienti. Dopo una prima fase di valutazione, a luglio 2022 è iniziato ufficialmente il pagamento delle due aziende farmaceutiche Shionogi e Pfizer, rispettivamente per l’antibiotico contro batteri multiresistenti cefiderocol e per il nuovo prodotto ceftazidime-avibactam.
AI non sembra una minaccia per il posto di lavoro dei ricercatori nella drug discovery
Una delle principali preoccupazioni destate dagli strumenti di IA è la sostituzione di posti di lavoro qualificati, come già discusso su Agenda17 da Riccardo Zese, ricercatore a tempo determinato del Dipartimento di scienze chimiche, farmaceutiche ed agrarie dell’Università di Ferrara.

Secondo Jonathan Stokes, professore associato alla McMaster University, che ha utilizzato tecnologie di deep learning per fare antibiotic discovery contro un batterio multiresistente, questi strumenti non rappresenterebbero una minaccia per il posto di lavoro dei ricercatori “ Io li vedo come un potenziamento delle nostre abilità per fare il nostro lavoro”. Sottolinea che non sono mai le macchine a lavorare da sole e avranno sempre bisogno di un input umano per l’ipotesi biologica iniziale, la generazione dei dataset e i test di validazione.
Il processo di identificazione di abaucin ha visto infatti una continua interazione tra ricercatori e bioinformatici, sottolineando la necessità della componente umana: come in una partita di ping pong, la pallina della ricerca passa dal bancone del laboratorio, dove è stato generato il dataset iniziale di molecole con capacità antimicrobiche e non per il training dell’algoritmo, al computer per la previsione delle molecole efficaci, e poi di nuovo al bancone per il test dei candidati. Seguono successivi passaggi avanti e indietro di rifinimento.
Anche Zese concorda “Secondo me rimarrà sempre quella necessità dell’operatore umano specializzato, magari specializzato in un task leggermente diverso. Però una guida per questi sistemi ancora deve esserci”. Mentre può essere un problema in altri ambiti, i posti di lavoro dei ricercatori nella drug discovery per il momento dovrebbero essere salvi.
I potenziali problemi: grandi dataset, energia e disparità di accesso
Il successo di questi strumenti dipende dalla qualità e dalla completezza dei database utilizzati per il training degli algoritmi. Questo è un primo limite degli strumenti computazionali “Molti di questi modelli, per come sono fatte le loro architetture, richiedono dei dataset molto grandi per il trainig” afferma Stokes, che in una lavoro di revisione pubblicato lo scorso agosto lancia una call to action per la condivisione dei set di dati utilizzati per l’addestramento degli algoritmi.

Anche se al momento esistono alcuni dataset pubblici per AMR, la mancanza di una standardizzazione nella registrazione dei dati e nella frequenza degli aggiornamenti limitano lo sviluppo di ottimali modelli predittivi basati su IA.
Un altro problema è quello energetico “Questi modelli sono sempre più grandi, hanno bisogno di sempre più potenza proprio di calcolo per poter essere eseguiti” spiega Zese. “Quindi c’è bisogno di computer molto grandi con degli hardware molto potenti. [..] Tanta potenza significa calore generato, significa energia elettrica consumata, significa che hai bisogno di grandi spazi e di soldi”. È quindi da tenere in considerazione anche l’impatto ambientale dell’intelligenza artificiale, oltre all’equità di accesso alle tecnologie a livello globale.
Infatti, se da un lato strumenti computazionali permettono di tagliare i costi dello sviluppo dei farmaci, e in ultimo di rendere l’acquisto accessibile a più persone, dall’altro sono tecnologie molto costose, per cui difficilmente Paesi più poveri potranno permettersi di utilizzarle e continueranno a dipendere dai più ricchi per la scoperta a sviluppo di nuovi farmaci.
Cosa c’è dentro la black box?
Infine, anche nell’ambito della drug discovery c’è l’inquietudine generata dall’incognita delle black box. “Black box vuol dire che io do in pasto all’algoritmo il mio set di dati per il training. La rete neurale processa e determina un modello di classificazione e mi dà il risultato che molto spesso è molto buono, ma io non so quello che ha fatto il modello” spiega Gabriele Costantino, direttore del Dipartimento di scienza degli alimenti e del farmaco dell’Università di Parma “e questo per i puristi – della drug discovery– era molto disturbante” aggiunge.

“Ci sono molti studi che cercano di trovare una spiegazione sul funzionamento di queste reti neurali” spiega Zese “è una cosa molto studiata ma ancora non si riesce a capire, e probabilmente non si riuscirà mai a capire come funzionano interamente”. In fondo, anche per l’intelligenza “umana” non siamo in grado di capire come le nostre reti neurali giungano a determinate soluzioni. E chissà se mai lo capiremo.
(Articolo aggiornato al 7 luglio 2023)